【Spark Summit East 2017】使用Spark, Kafka和Elastic Search的大规模预测
本文共 177 字,大约阅读时间需要 1 分钟。
更多精彩内容参见云栖社区大数据频道;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问。
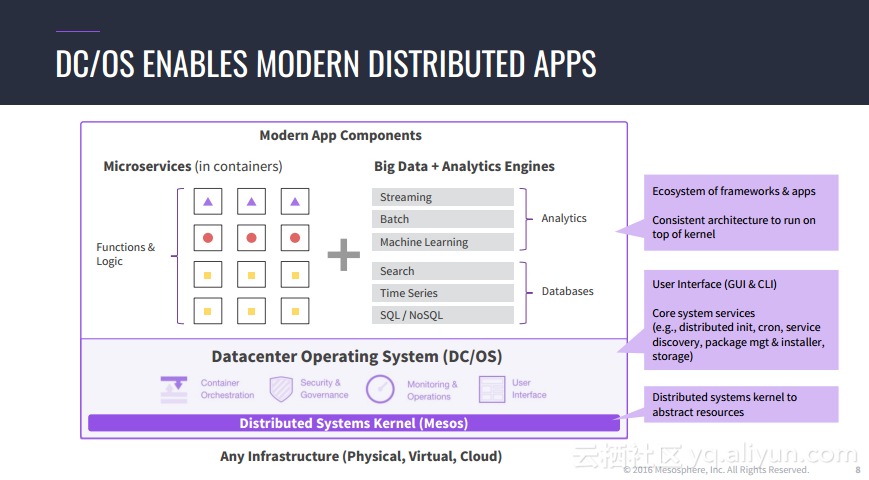
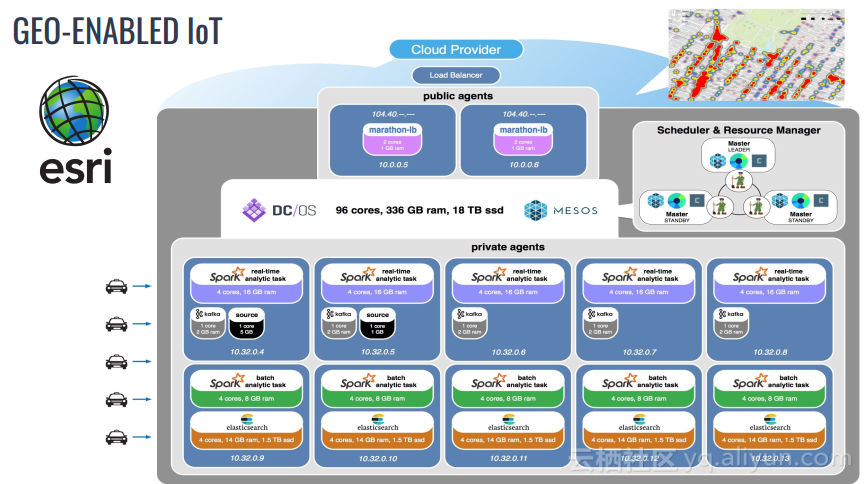
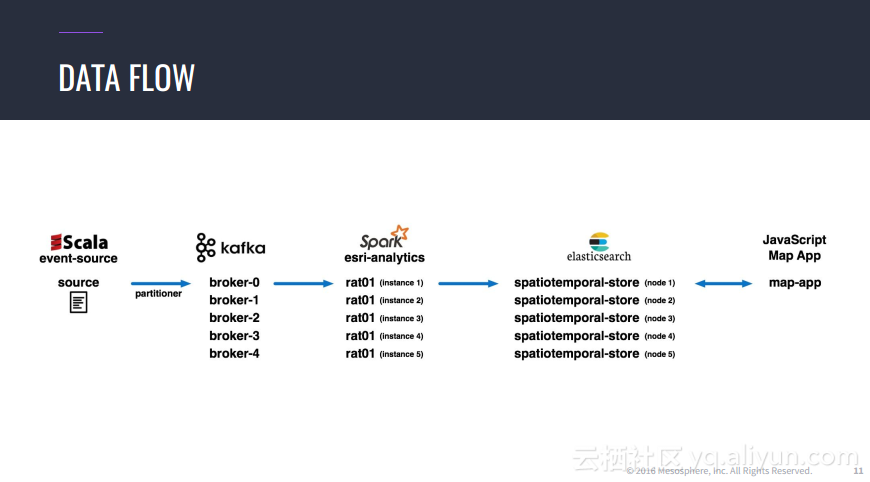
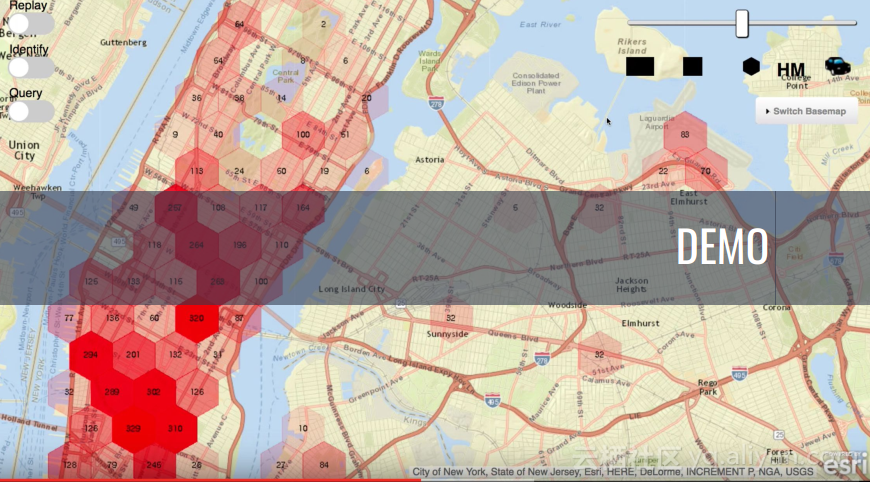
本讲义出自Jorg Schad在Spark Summit East 2017上的演讲,主要介绍了使用Spark, Kafka和Elastic Search的大规模预测的方法以及案例,并分享了分布式计算以及数据分析预测应用的架构设计思想。


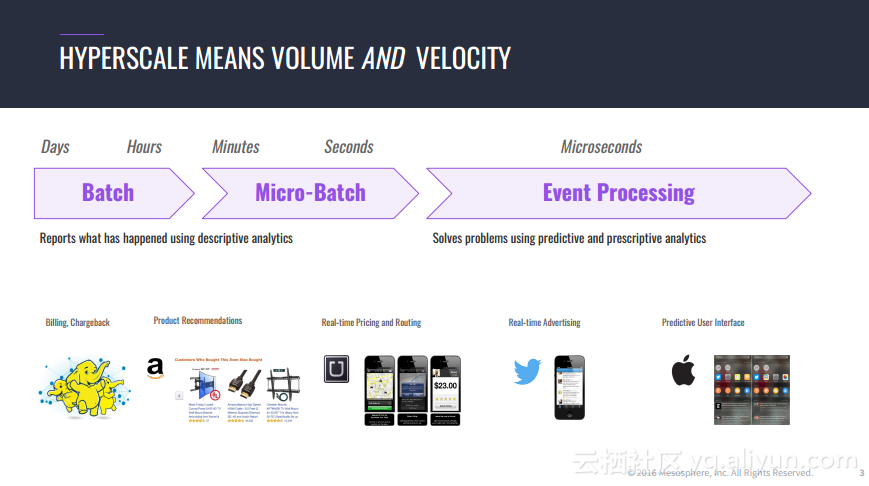
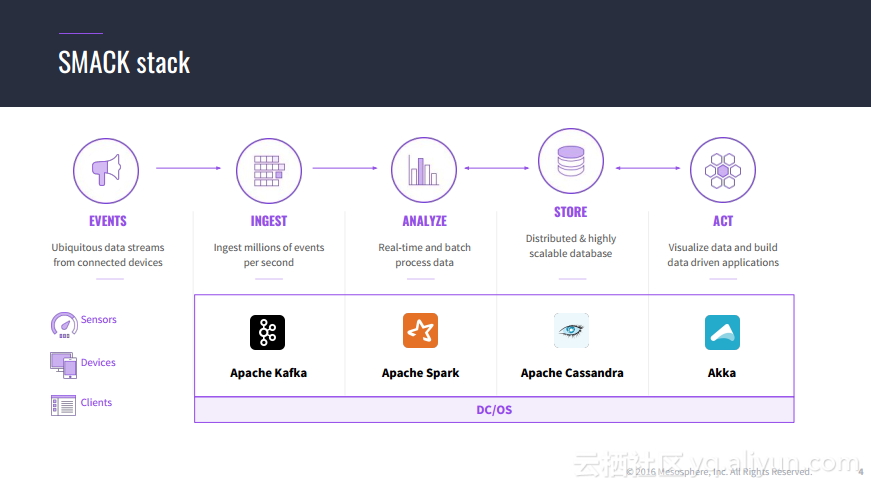
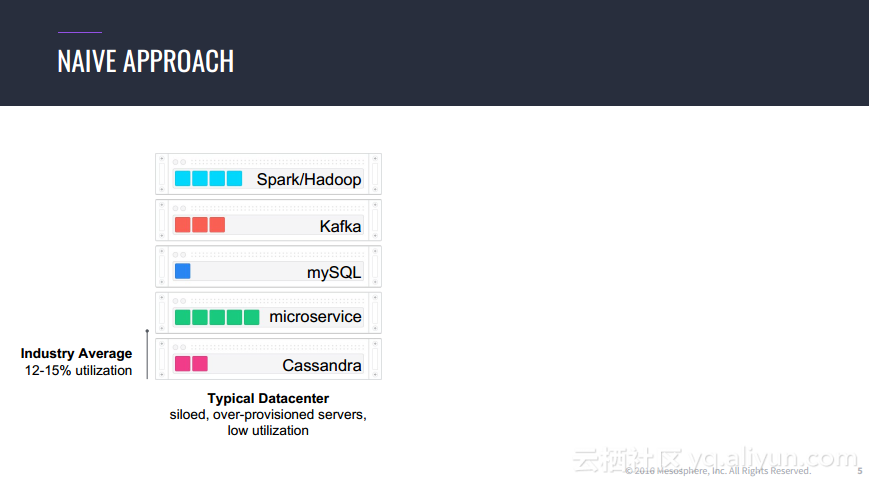

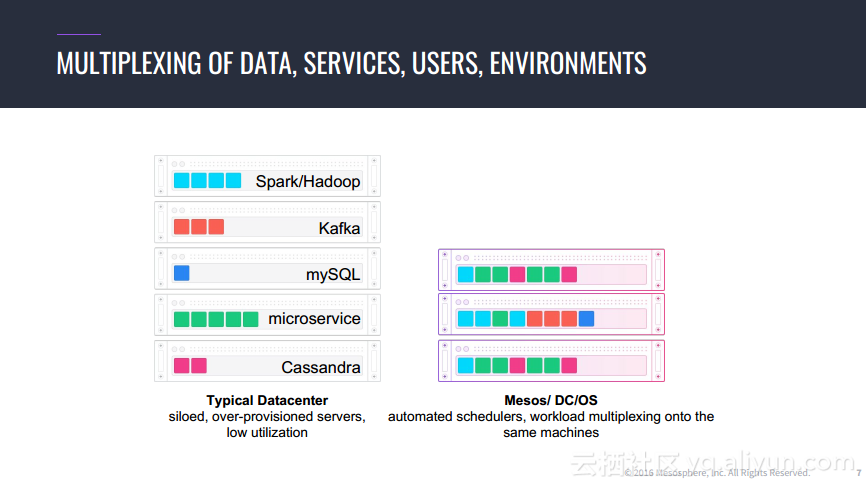


转载地址:http://ocvxl.baihongyu.com/
你可能感兴趣的文章
高性能WEB开发应用指南
查看>>
根据从数据库中获取到的值控制按钮被选中
查看>>
接口要怎么对?你知道正确的姿势吗
查看>>
配置mysql数据库集群
查看>>
TensorFlow分布式实践
查看>>
缺失值及处理
查看>>
我的友情链接
查看>>
msyql root无权限登录
查看>>
Ajax理解
查看>>
第一次模拟建站2
查看>>
linux 系统审计audit详解
查看>>
linux命令行下的ftp多文件下载和目录下载
查看>>
JAVA对象克隆
查看>>
MySQL审计插件使用
查看>>
我的友情链接
查看>>
关于securecrt7.2版本安装在win8系统激活的问题
查看>>
我的友情链接
查看>>
C028 unable to connect to siebel gateway name server
查看>>
PLSQL Developer连接远程Oracle数据库
查看>>
JS一个非常经典的问题:在遍历数组时对DOM监听事件,索引值将始终等于遍历结束后的值...
查看>>